Mimicking Human Continual Learning in a Neural Network

A large portion of human intelligence can be attributed to a concept known as continual or lifelong learning. Essentially, this is when we can use previous knowledge and apply it to a current scenario. This concept is fundamental to our ability to learn and generalize information.
For example, if an infant encounters a new object that is similar to something they have seen and understood before, they predict what the new object is based on their past knowledge.
This same concept is a major bottleneck in machine learning, limiting one model to train and achieve high accuracy on one task, but then be unable to use that knowledge for future projects.
In this project, I decided to mimic human continual learning to allow a machine learning model to apply what it’s learned previously. I tackle two different image classification tasks, one on the MNIST database and one on the SHVN (Street View House Numbers) database. The goal is to produce one single model that can correctly classify images from the MNIST and SHVN models with a high accuracy.
Before I get started, this project is based on the framework provided in this paper: Continual Learning with Deep Generative Replay.
The framework employs one scholar for each task. A scholar is a set of 2 models, made up of one generator and one solver. In our case, the generator is a Wasserstein Generative Adversarial Network with Gradient Penalty (WGAN-GP) and the solver is a Convolutional Neural Network (CNN).
GANs
A generative adversarial network is a generative neural network made up of a generator and a discriminator.

The generator learns to generate synthetic data with the goal of mimicking real data as closely as possible. The discriminator learns to distinguish real data and the generator’s fake data. The backpropagation is carried out through using the discriminator’s output to update the weights of the generator.
The discriminator loss explains the accuracy of classifying real or fake data, whereas the generator loss which penalizes the generator for failing to fool the discriminator.
Discriminator
The discriminator is a classifier that uses real data (from a dataset) as positive examples, whereas fake data (by the generator) as negative examples.
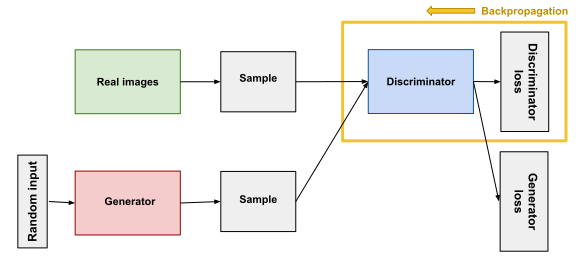
How the training of the discriminator works:
- Classifies the real and fake data
- The discriminator loss function increases the more it wrongfully classifies the data
- Updates its weights through backpropagation
Generator
The goal of the generator is to incorporate the feedback from the discriminator to try to get it to classify the generated fake data as real.
The GAN uses random noise as its input to generate a wide variety of data, through sampling from different places in the normal distribution. Keep in mind that the specific distribution doesn’t matter, its just a way to represent different aspects of the images the generator is trying to reproduce.
Unlike a traditional neural network, the generator isn’t directly connected to its loss, the discriminator is the middle man. The generator loss increases as the generator produces more data that the discriminator classifies as fake.

Backpropagation is based on the fundamental principle of calculating a certain weight’s impact on the output, but in this case the impact of a generator weight depends on the discriminator weight. Backpropagation starts at the output, works backwards through the discriminator, and then into the generator. Therefore, as the generator is training, the discriminator stays the same.
Process for training the generator:
- Sample random noise
- Generator produces an output based on the noise
- Discriminator classifies generator output as “real” or “fake”
- Calculate generator loss from discriminator classification
- Backpropagation through the discriminator and the generator
5.5 Generate gradient for discriminator and generator
6. Use generator gradient to alter weights of the generator only
Training the GAN
The training algorithm must juggle the training of the generator and the discriminator, which makes reaching convergence difficult. The algorithm alternates between training, keeping one the same when training the other one.
The discriminator is trying to identify the flaws in the generator that allow it to distinguish between real and fake data. The generator is trying to optimize its output so the flawed discriminator classifies it as real.
As the generator improves, the discriminator decreases because it has trouble identifying real from fake data. Theoretically, if the generator becomes perfect, then the discriminator will have a 50% accuracy (essentially a random guess between “real” or “fake”).
One issue with the convergence in a GAN is the discriminator feedback becomes less meaningful over time. If the GAN trains too much then the discriminator’s feedback will become random, and the generator will decrease by trying to optimize for the wrong thing.
Loss Function
The goal of a GAN is to replicate a probability distribution of the real data, using the data generated by a GAN. Both the loss functions (generator and discriminator) are derived from one function representing the distance between probability distributions.
One important thing to understand is that in the total loss function, the generator can only affect the term representing the fake data (because it doesn’t deal with real data at all). Therefore during generator training, we only focus on the distribution of fake data, ignoring the distribution of real data
The loss function used is Minimax Loss, which calculates the cross-entropy between two data distributions.

WGANs
In a Wasserstein GAN, the discriminator doesn’t classify the data as real or fake, instead it outputs a scalar number.
The critic (same function as a discriminator but it doesn’t discriminate between real or fake) tries to make the output number larger for real data than fake data. It is called a critic because the linear output can be thought to represent how “real” the discriminator things an image is.
Critic Loss (Maximize)

This focuses on maximizing the difference between the output number for real data D(x) and the fake data D(G(z))
Generator Loss (Minimize)

Similar as the Minimax loss, it tries to maximize the output number (not a probability) for a generated fake data instance
WGAN-GP
One condition on the critic in a WGAN is that it needs to be 1-Lipschitz continuous. What this means is the norm of the gradient (slope) cannot be greater than 1 or less than -1 for every single point. This condition is important to make sure the Wasserstein Loss is stable and doesn’t grow too quickly.
There are two methods to enforce 1-L continuity when training the critic: weight clipping and gradient penalty.
Weight clipping is when the weights of the critic after gradient descent are clipped to a fixed interval. Essentially, if the weight is too high it will be set to the max of the interval and similar for too low.
The major downside is that it limits the learning ability of the critic, which could decrease the efficacy of the overall WGAN.
Gradient Penalty is when a regularization term is added to the loss function, whose job is to penalize the critic if the norm is higher than 1 (or lower than -1).

The process for implementing gradient penalty is as follows:
- Interpolate between a real image and a generated image using a random value, ϵ for real and 1 — ϵ for fake. For example, if ϵ= 0.3. then the interpolated image (x̂) is 30% real, 70% fake.
- Penalize the norm of the gradient, of the interpolated image, if its greater than 1 (at every point). Squaring it just penalizes the value more the further away it is from 1
Benefits of WGANs
WGANs are less vulnerable to getting stuck and prevent the problems of mode collapse and vanishing gradient, because it isn’t bounded meaning that the generator will always get useful feedback from the discriminator.
Another benefit is that the loss function is a true metric, the distance in a space of probability distributions, as opposed to cross-entropy.
Training Pipeline
Training the first scholar follows the common procedure. We train the WGAN-GP to generate realistic images of handwritten digits, and we train the CNN to classify handwritten digits.
Training the second scholar is where the power of this framework comes into play.
In order to train the second scholar’s generator, which is the WGAN-GP for the SHVN database, we input a combination of data. The first 50% is from the actual SHVN dataset and the other 50% as the generated images of MNIST (from the first generator). GANs are an unsupervised learning model, explaining why they can be trained on only the images without their labels.

Training the second scholar’s solver is more complicated because a CNN is a supervised learning model, meaning it needs to be trained on the images and their labels.
Similar to the generator, we input another 50–50% split of the dataset and the previous scholar. As is visible in the diagram below, in order to train the second solver, we need to produce labels (y`) for the generated images (x`).In order to do that, we use the CNN we trained in the first scholar.
The first 50% are the images and labels from the SHVN dataset, while the second 50% are the generated images and their corresponding labels.

Intuition
Essentially, the framework can be simplified to training the new scholar on 50% new data and 50% generated data from the previous tasks.
Speaking of which, this framework is known as Deep Generative Replay, because it works on generated versions of previous data instead of using real examples of previous data (known as exact replay).
The reason for this is to make it more applicable in real-world scenarios. In the real-world, we may not have access to the previous data forever or there may be privacy concerns or other issues that prevent us from reusing it.
An even bigger issue is the storage of data. Imagine how impractical it would be to store a portion of the data for every task we encounter.
Deep Generative Replay allows us to continually build upon this stack of scholars, enabling the term continual learning. If I wanted to train on another dataset, I would just repeat the architecture above, and so on.
One last point is that I chose to incorporate the data at a 50–50 split, but this value can change depending on the importance of the new task with respect to the previous ones.
In case this entire framework doesn’t make sense, think about it this way.
Imagine we just trained a CNN on the MNIST dataset, as is the status quo. Now if we were to feed in some SHVN images, the model would perform pretty poorly (there will be some knowledge transfer because both tasks are numbers, but nowhere near close required accuracy).
Employing deep generative replay, our final CNN (second scholar) can now classify both SHVN and CNN images to a very high degree of accuracy.
If we were to add another task, such as the Digits dataset, and extend the framework, the CNN would be able to classify images from all three.
Code
All the code for this project is available on my Github at:
MNIST Generator (First Scholar)
Following standard procedure, the goal of this section is to train the WGAN-GP to generate realistic images based on the MNIST dataset.
We begin by defining the architecture for our Generator and Discriminator (Critic) and the Gradient Penalty function. The hyperparameters are pretty standard and the reason for loading the model is that training was done in sets of 10–20 epochs at a time, for a total of 40.
After importing the dataset, we build the training algorithm. Simplified, we cycle through each image in the dataset and feed it in as the real image. WGANs require a special addition where the critic is trained much more frequently than the generator to stabilize training, in our case 5 times as often.
In order to train the critic, we generate the random noise vector and run it through the generator to create our fake image. We then calculate our loss function for the real image and the fake image and the gradient penalty of the interpolated image between the two. To conclude, we just implement the Wasserstein loss function from above.
Similarly to train the generator, we take the inverse of the Wasserstein function from above, because we are trying to maximize this value but Pytorch always minimizes the loss function.
The printing and saving images is just to visualize the training of the GAN.
In the notebook below, we want to load the pre-trained model from above and use it to generate 30k (half of a traditional dataset) images.
We need to define the generator class and structure and then load the model’s weights and biases.
To generate the images, we define our random noise and then run it through the generator. However this outputs a 64 x 64 image, so we save that to a temporary location and then resize it to 28 x 28. Once again, in this case the model was trained in 3 iterations of 10,000 images.
MNIST Solver (First Scholar)
This notebook has two functions relating to the CNN.
First, we train the CNN normally: load in the dataset, initialize the structure, define the training and testing algorithms and run.
Once the CNN is trained (I believe the accuracy is about 98%), we then leverage this model to classify the 30k generated MNIST images.
After some thinking, the best way to tackle this is to instead of having all the images in one big directory, separating them folders depending on their label. For example, all the 1s in one folder, 2s in another, etc.
The reason for this is that it is directly compliant with Pytorch’s ImageFolder function, which is vital for loading data in the second scholar.
Implementing this in code involves opening the image as a Pillow image and then converting it to a tensor and doing the necessary preprocessing. Once that is done, we can run it through the CNN and use Argmax to figure out which index in has the highest probably. That corresponds to the label for the image, from which we can copy the image into the designated folder.
SHVN Generator (Second Solver)
Moving into the second scholar, for this GAN we have the same goal of outputting unlabelled images, but with 50% coming from the SHVN dataset and 50% from our generated MNIST images.
The major difference in the second GAN is the loading of the data. We start by loading in the entire SHVN dataset and then using the Subset() function to get the first 30k images. This represents the first 50% of our data.
Due to the fact that GANs are unsupervised, we load the data from the original massive 30k image folder. We then combine both the datasets and create our data loader.
The rest of the pipeline is the same as the first GAN.
Note: The output of the second GAN isn’t actually required when there are only 2 tasks, it is only required if we were to extend the model and add a third task.
SHVN Solver (Second Solver — Final Model)
The second solver, the final model, is a CNN trained on equal distributions of both the SHVN dataset and our own generated MNIST dataset.
To load the SHVN half, we start by loading the dataset and taking a subset of 25k for training and 5k for testing.
We then use the ImageFolder() function to load our MNIST images, along with their labels. The random_split() function splits the dataset (without overlap) into the training and test set.
After combining the training and test datasets and data loaders, we can train our model.
The SHVN dataset is 32 x 32 whereas the MNIST is 28 x 28, so in this case we resize the MNIST to match SHVN. We also make some changes to the architecture of the CNN, to make it better suited for classifying SHVN images.
The rest of the training follows the exact same algorithm as the first CNN.
Results

As you can from the clipped output above, the final CNN, which was the SHVN solver for the second scholar, achieved an accuracy of 90% when tested on both MNIST and SHVN images.
Goal: Accomplished ✅
I’d say this was a very successful project in terms of growing my technical abilities significantly, but also just the accuracy rate of the model!
